
Context Engineering: How AI Turns Email Chaos into Searchable Intelligence
Email is where critical business information goes to die. Important decisions, agreements, project updates, and customer feedback are buried in thousands of unstructured messages across dozens of threads. This article demonstrates context engineering principles through a practical project: building an AI system that transforms email chaos into searchable, structured intelligence.
The system follows a classic context engineering pipeline. First, email content is extracted and cleaned, stripping signatures, quoted replies, and formatting artifacts to isolate the actual information content. Then, each email is processed through an entity extraction and categorization step that identifies key entities (people, companies, projects, dates, amounts), classifies the email type (decision, request, update, question), and extracts actionable items. This structured data is stored alongside vector embeddings of the original content, enabling both keyword search and semantic search.
The intelligence layer is where context engineering really shines. When a user asks a question like "What did we decide about the Q3 pricing changes?", the system assembles context by retrieving relevant emails via semantic search, following conversation threads to capture the full discussion, identifying the key decision-makers involved, and constructing a timeline of how the decision evolved. This assembled context is then passed to an LLM that synthesizes a clear, sourced answer. The article walks through each component with code examples, covering email parsing strategies, embedding model selection, metadata schema design, retrieval optimization, and prompt engineering for the synthesis step. It's a complete blueprint for applying context engineering to any domain with unstructured information.
TL;DR
A practical walkthrough of building an AI-powered email intelligence system using context engineering principles.
Key Takeaways
Context engineering transforms unstructured data (like emails) into searchable intelligence through extraction, categorization, and structured retrieval.
The pipeline: clean content, extract entities, categorize by type, store with embeddings, and assemble rich context for LLM synthesis.
Combine semantic search with metadata filtering and thread-following to build complete context for complex queries.
This pattern applies to any domain with unstructured information, emails, Slack messages, support tickets, meeting notes.
Your inbox holds thousands of conversations. Buried somewhere in those threads is the contract your client mentioned last week, the deployment timeline your team debated last month, and the budget decision that happened across three separate email chains. When you need to find something, you don’t just search for keywords. You remember context: who said it, when it happened, what else was going on at the time.
This is what separates finding an email from understanding your email. Traditional search gives you messages containing certain words. Intelligence gives you meaning, relationships, and answers synthesized from the full story of your communications.
Most email tools are fancy filing cabinets. You can search for keywords, filter by sender or date, and organize with labels. But they can’t read context across threads, understand what decisions were made, or connect a customer complaint from January with the product fix discussed in March. Your email contains valuable intelligence, but until recently, no system could extract it.
A new generation of tools treats your inbox as a living knowledge base. These systems read full conversations like humans do, understand relationships between threads, extract decisions and tasks, and answer questions by pulling together information from dozens of emails.
I recently joined iGPT as a partner, and the technology behind it is fascinating. The system uses sophisticated context engineering to turn email and workplace data into structured intelligence. They’re currently accepting people to their waiting list if you want to try it.
What follows is a technical deep dive into iGPT’s algorithm and how it actually works under the hood.
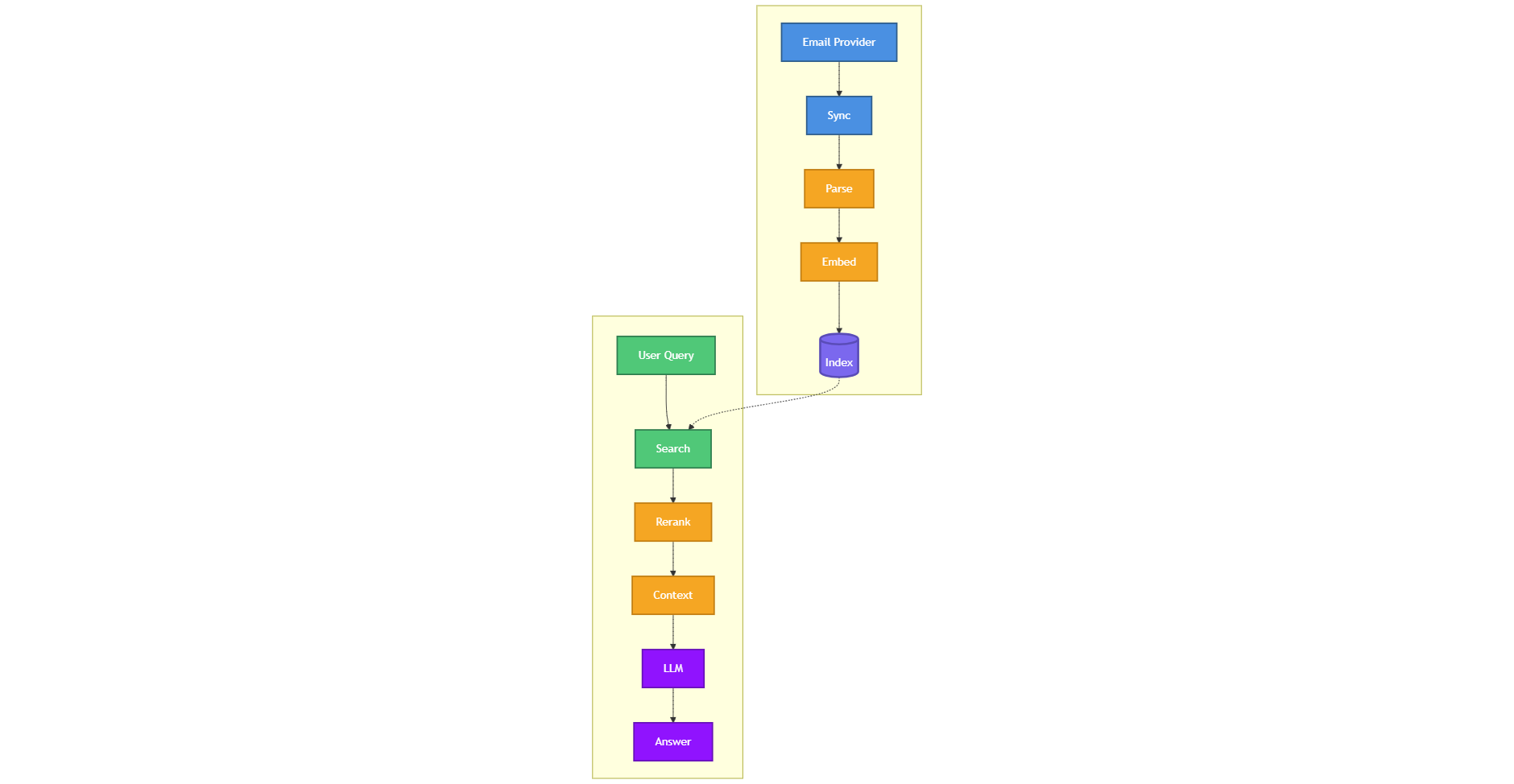
Syncing Millions of Messages Without Chaos
Imagine a moving company transferring everything from your old apartment. They can’t just grab random boxes. They need a strategy: start with essentials you’ll need tonight, then work systematically through everything else, while staying alert for new items you’re still packing.
This is exactly what happens when you first connect your email account to iGPT. The system might need to sync millions of messages, and it has to be smart about priorities.
The sync runs in two directions simultaneously. It fetches existing emails starting from the newest and working backward, since recent conversations matter most. But while this historical sync happens, new emails keep arriving. These fresh messages jump to the front of the line, getting processed within seconds so the system stays current.
For a typical email without attachments, the system makes it searchable in about one second. Complex emails with PDF attachments that need text extraction might take 20 seconds, but this happens in the background without slowing anything down. The system works with all major email providers through their APIs or the universal IMAP protocol, pulling everything: email bodies, metadata, and every attachment.
Extracting Clean Content from Messy Email
Raw email is incredibly messy. HTML newsletters have complex formatting. Reply chains quote the same text five levels deep. Email signatures bloat every message. Threading conventions vary by email client.
The trickiest challenge is handling email threads. When you reply to an email, your client typically includes the entire previous conversation below your response. If ten people exchange messages, the final email contains all nine previous messages nested inside it. A basic system would treat each reply as separate, creating massive duplication.
The solution is clever. Because sync starts from newest emails first, the system often sees a recent reply that quotes several older messages before encountering those originals. It processes what it has but marks the quoted sections. Then, as sync continues backward through time and reaches the original emails, it revisits the newer messages and strips out duplicates. This iterative cleaning continues until every message in the thread appears cleanly exactly once.
HTML emails get converted to clean Markdown format, preserving structure like headers and lists while removing styling clutter. Newsletters go through an algorithm that extracts actual article content from navigation menus and footers, similar to browser reading modes. The system ignores spam and trash automatically but keeps newsletters since they might contain work-relevant information.
How Hybrid Search Finds What You Actually Mean
You ask: “What did my team decide about the API redesign?” This question lacks obvious keywords. “API redesign” might appear in subject lines, but the actual decision could be buried in a message saying “Let’s go with Option B” without ever repeating those exact terms.
Traditional keyword search falls short here. You need a system that understands meaning, not just matches words.
The approach uses hybrid search, combining three complementary methods. Full-text search finds emails that literally contain your search terms. This catches exact matches and runs incredibly fast.
Semantic search operates deeper. The system converts all emails into numerical representations that capture meaning. When you search, your question gets the same treatment, and the system finds emails that are semantically similar even with different words. A search for “API redesign decision” might surface an email discussing “endpoint architecture consensus” because the models understand these concepts relate.
Filter-based search handles structured queries about dates, senders, or metadata. “What did Sarah say about this last month” becomes filters that narrow results before semantic matching begins.
Each method produces candidates with confidence scores. The system combines these intelligently. An email matching both semantic meaning and keywords scores higher than one matching only semantically. Then comes reranking, where a specialized model reassesses all candidates in context of your specific question, boosting truly relevant results and filtering false positives.
Assembling Context That Makes Sense
Finding relevant emails is only half the work. Now the system must construct context that helps a language model actually answer your question.
Think of a museum curator building an exhibition. They have thousands of artifacts in storage but carefully select specific pieces, arrange them meaningfully, and provide labels that help visitors understand what they’re seeing.
The system reconstructs retrieved emails into a coherent narrative. It includes essential metadata: who sent each message, when, and the subject. It organizes messages chronologically when showing a thread’s evolution, or thematically when multiple threads discuss the same topic. For long threads, it identifies which parts matter most to your question rather than including everything.
This assembled context gets structured so the language model can cite sources properly. Each piece of information is tagged with its origin. When the model generates an answer, it points back to specific emails. You’re one click away from verifying any claim or diving deeper into the original conversation.
The system manages token limits dynamically. If retrieval pulls dozens of relevant emails that would exceed the language model’s capacity, it summarizes less critical portions while preserving the most relevant details in full. This balancing act considers technical limits, cost, and speed.
Achieving reliable citations required serious engineering effort. The system must track which parts of its answer came from which sources even as the language model synthesizes information from multiple emails. Getting this right means every claim can be verified instantly, transforming the experience from “the AI told me something” to “here’s what actually happened, with proof.”
Privacy, Security, and Speed at Scale
All email data sits encrypted at rest with per-user and per-message encryption keys. The system never uses your data for model training. When you disconnect your account, everything gets deleted within 24 hours after confirming it wasn’t just a temporary authentication problem.
Despite all this processing, retrieval, ranking, context assembly, and generation, the system targets about three seconds from question to answer.
The initial retrieval searching through millions of emails completes in under 100 milliseconds. This speed comes from careful indexing and optimization. Recency-based caching keeps frequently accessed recent emails hot in memory. Parallel processing means multiple steps happen simultaneously rather than sequentially.
The system constantly evaluates performance, switching between different models and approaches when something faster or better becomes available. It can even run multiple embedding models in parallel during transitions so service never gets disrupted during upgrades.
Users with millions of emails see no performance degradation. The architecture scales because each step is optimized independently: fast retrieval, efficient reranking, smart context assembly, and careful token management.
Related Tutorials
Free Resources
Download free guides, cheatsheets, and templates curated from 130+ tutorials on RAG, AI Agents, and Prompt Engineering.
Also available on Substack
Prefer Substack? This article is also on our newsletter, read by 40K+ AI engineers.
Related Articles
How to Stop AI Hallucinations
AI hallucinations are one of the biggest challenges in production AI. Here are battle-tested techniques to minimize and control them.
Graph RAG Explained
How Graph RAG combines knowledge graphs with retrieval-augmented generation to deliver more accurate, structured, and contextual AI responses.
Controllable Agent for Complex RAG Tasks
How to build controllable agents that handle complex RAG workflows, with user-guided retrieval strategies and transparent decision-making.
Get More AI Insights Weekly
Join 40K+ AI engineers getting deep dives on agents, RAG, and prompt engineering every week.